
Gemma 4 and Qwen 3.6 with q8_0 and q4_0 KV cache: KL divergence results
4 models tested with q8_0 and q4_0 KV cache against full-precision baseline

What this measures
KV cache quantization stores the key-value cache in lower precision to save memory. q8_0 halves the cache memory, q4_0 quarters it. The common wisdom is that q8_0 is “practically lossless.”
Each model was tested using the BF16 GGUF from Unsloth, loaded three times with f16, q8_0, and q4_0 cache on the same machine. The only variable changing between runs is cache precision. These measurements include the recently added TurboQuant-inspired attention rotation that llama.cpp applies automatically. Full methodology.
Results
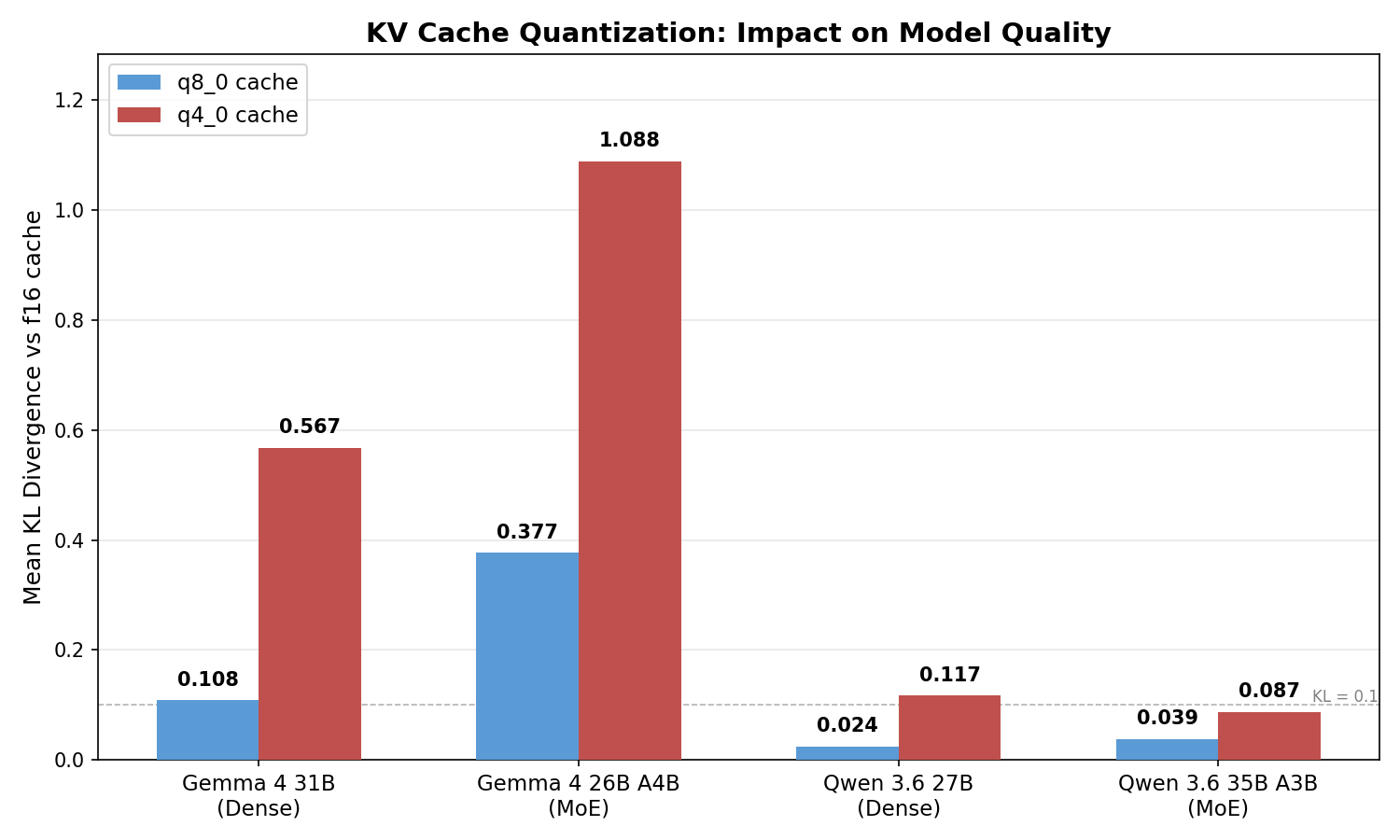
Findings
Gemma is sensitive to KV cache quantization, Qwen is not
“q8_0 is practically lossless” is wrong for Gemma.
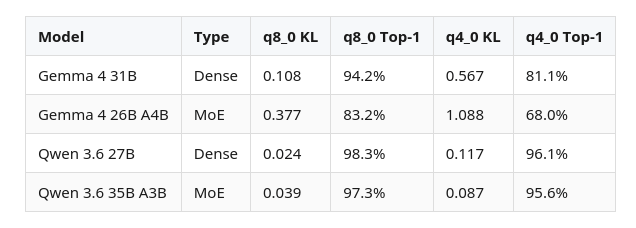
Gemma 31B at q8_0 cache has KL 0.108. Gemma 26B A4B at q8_0 is 0.377. Qwen handles it much better: both Qwen models stay below KL 0.04 at q8_0, and even q4_0 cache (KL 0.087-0.117) is usable.
MoE amplifies the problem for Gemma
The Gemma 4 26B A4B is the most quantization-sensitive model tested so far, both for weights and for KV cache. Its q8_0 cache KL (0.377) is 3.5x worse than the dense Gemma 31B (0.108), and q4_0 reaches KL 1.088 with 68.0% top-1. Qwen’s MoE shows no such amplification (0.024 dense, 0.039 MoE).
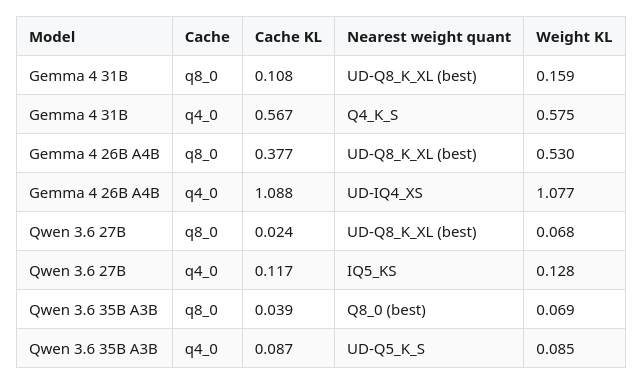
How cache quant compares to weight quant
Cache quantization and weight quantization are independent sources of quality loss. If you run a Q4_K_M with q8_0 cache, both penalties stack. The table below maps each cache result to the weight quant that causes equivalent damage.
Full weight quant benchmarks: Gemma 4 31B, Gemma 4 26B A4B, Qwen 3.6 27B, Qwen 3.6 35B A3B.
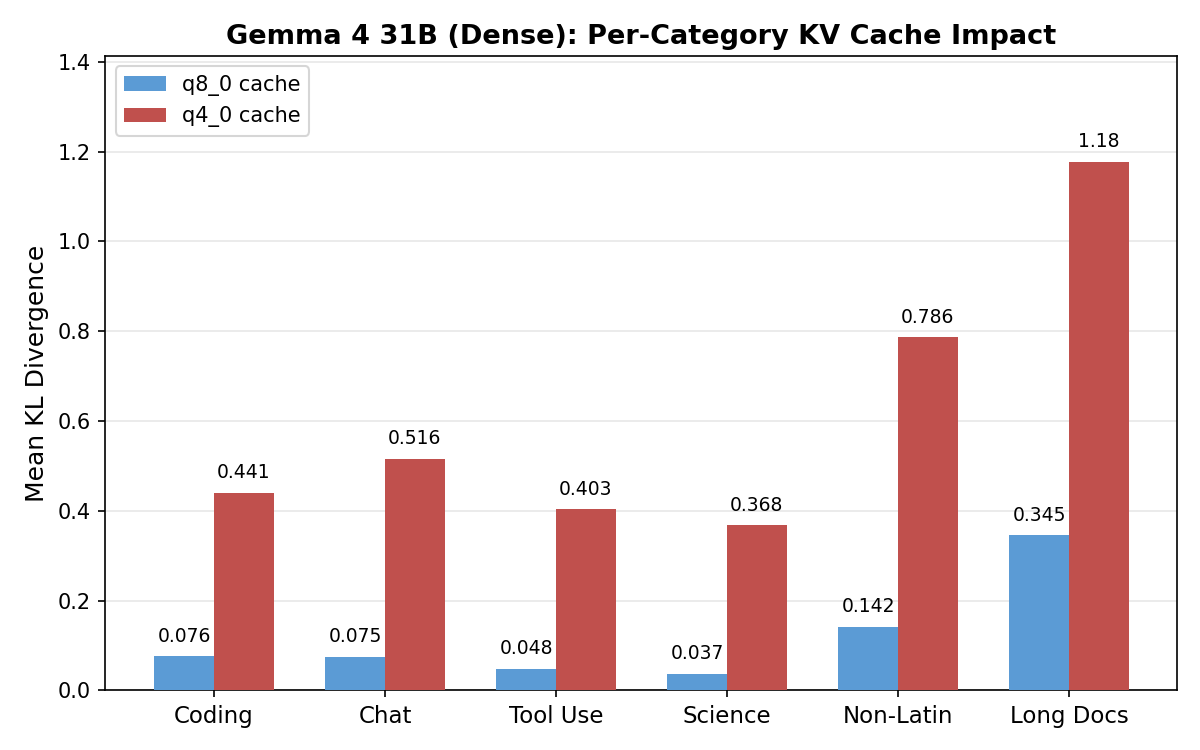
Per-category: Gemma degrades everywhere, Qwen only on long docs
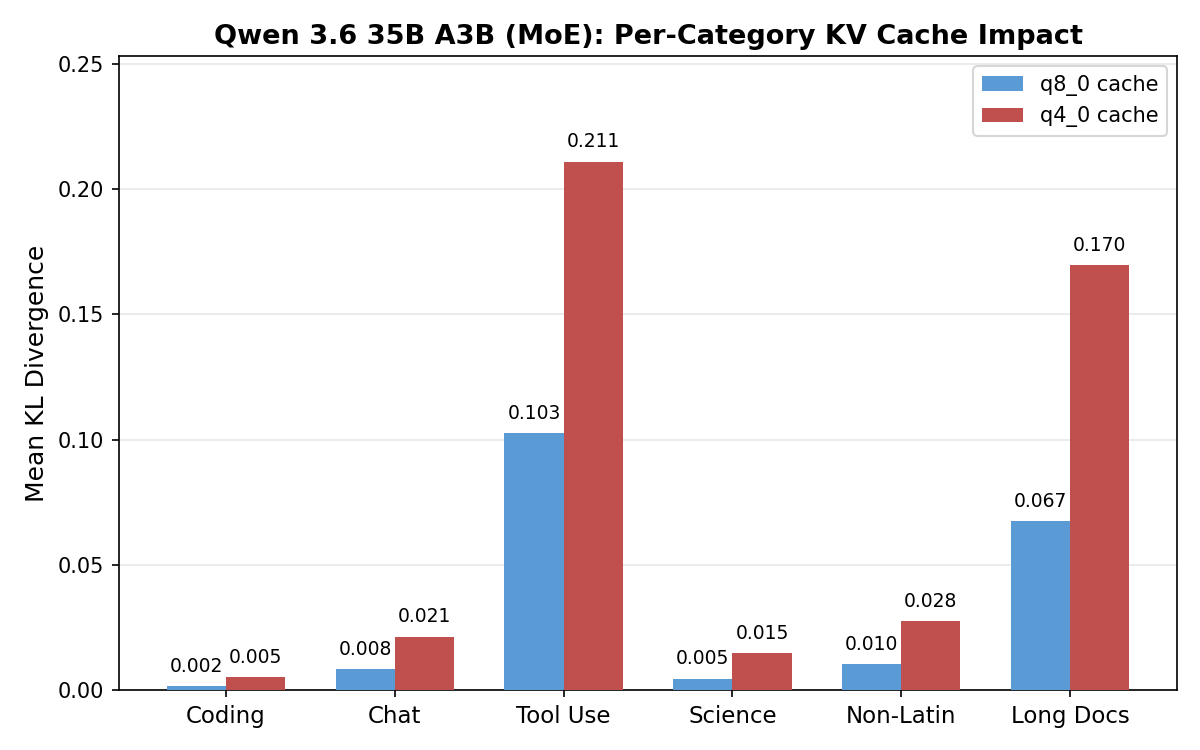
Gemma degrades uniformly: even its best category at q8_0 (science, KL 0.214) is worse than Qwen’s worst (long docs, KL 0.142). Qwen concentrates nearly all damage in long documents (KL 0.581 at q4_0) and tool calling (0.086), with other categories staying near zero.
Per-category performance
Gemma 4 31B (Dense)
Gemma 4 26B A4B (MoE)
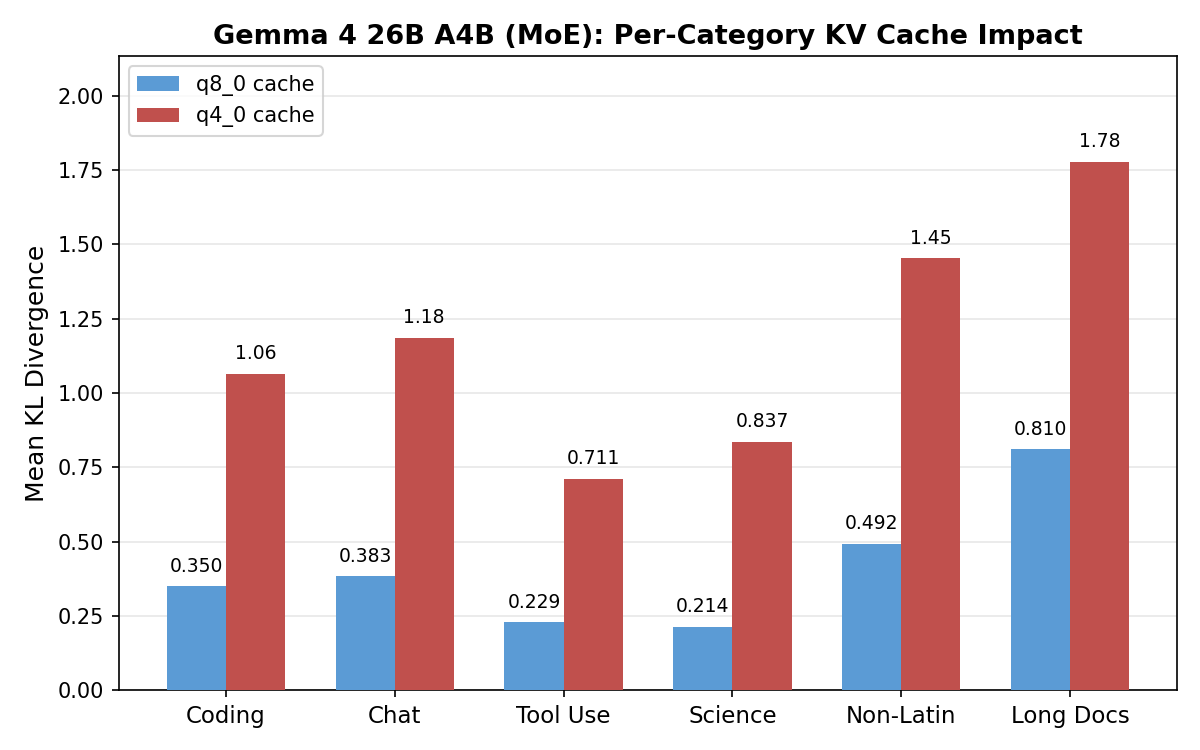
Qwen 3.6 27B (Dense)
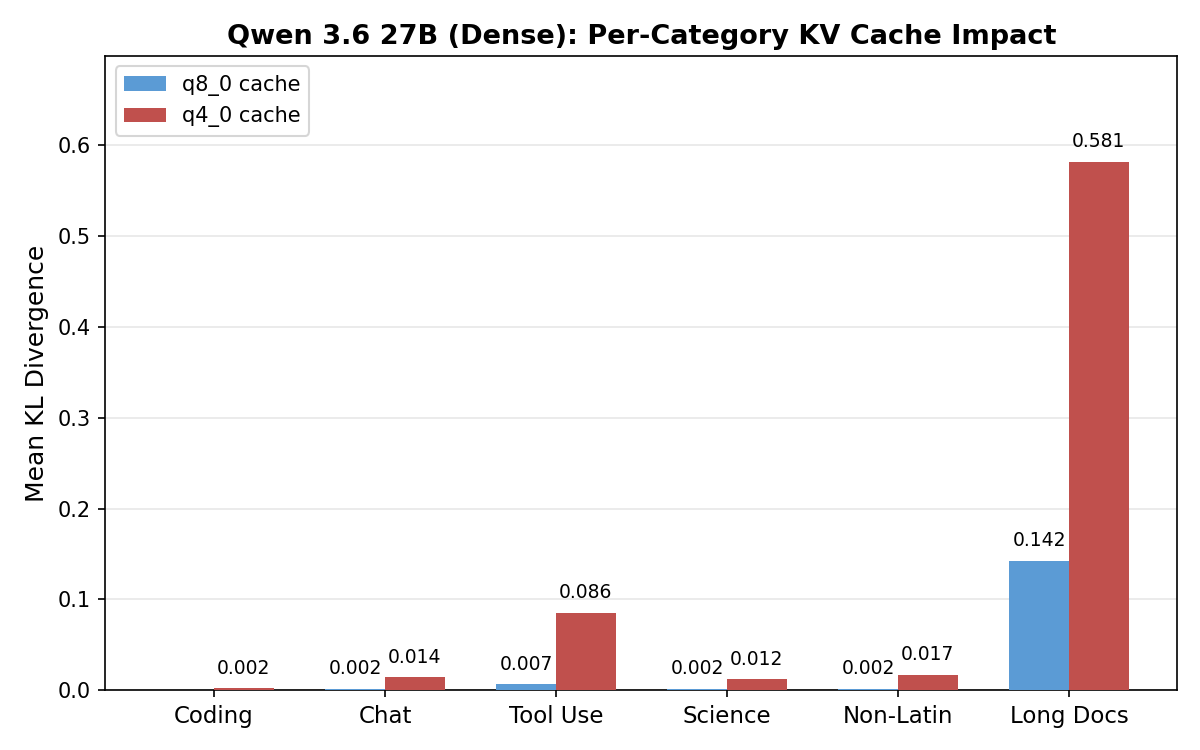
Qwen 3.6 35B A3B (MoE)
Methodology
Inference: TextGen + patched llama.cpp (logprob extraction from prompt)
Reference: BF16 GGUF loaded with f16 KV cache (the llama.cpp default)
Test: Same BF16 GGUF loaded with q8_0 or q4_0 KV cache
Dataset: ~250,000 tokens across 6 categories (coding, general chat, tool calling, science, non-Latin scripts, long documents)
Metric: KL divergence, computed token-by-token between f16-cache and quantized-cache top-40 log-probability distributions
Would be nice if you tested split KV caching (i.e. quant just V-cache, keep K at full precision) since key is much more sensitive to quantization than value. Thanks so much for doing this work!